Oracle In-Memory Performance ohne Lizenzkosten
Im einem unserer Kundenprojekte werden für eine Bundesbehörde die Daten von ärztlichen Behandlungskosten ausgewertet. Hierfür sind teils komplexe Auswertungen nötig, die in weiten Teilen mit dem Oracle Analytics Server (OAS) in Echtzeit erfolgen. Um für die Anwender von Ad-Hoc-Reports keine allzu langen Wartezeiten entstehen zu lassen, wird seit 2021 die Oracle In-Memory Option verwendet, und zwar in der lizenzfreien Base-Level-Variante. Da diese nur die Bereitstellung von 16GB Daten zulässt, wurde ein reduzierter Data Mart entworfen. Auf diese Weise ist trotz der Limitierungen der kostenlosen In-Memory-Variante eine messbare Beschleunigung der Abfragen möglich geworden.
Komplexe Abfragen
Der Datamart des Data Warehouse (DWH) beherbergt 420 Millionen Fakten zuzüglich der entsprechenden Dimensionen. Die Auswertungen bestehen sowohl aus Standardberichten als auch aus interaktiven „Drill Down Reports”. Aus der Zeitdimension und den Dimensionen der zuständigen Bearbeitungsbehörden und Kunden werden für diese Berichte Hierarchien gebildet, die sich je nach Auswertung neu gruppieren. In den Auswertungen spielen die Laufzeiten der Anträge verteilt auf die Bearbeitungsstelle und bestimmte zu errechnende Intervalle (Wochen, Monate und bestimmte Meilensteine in der Antragsbearbeitung) eine entscheidende Rolle. Die fachliche Logik für die so errechneten Kennzahlen wurde im BI-Team zu den ursprünglich vorhandenen Anforderungen ergänzt oder sogar neu erstellt. Die Entwicklung wurde teilweise parallel zur Festschreibung der Anforderungen quasi agil vorangetrieben. Aus diesen Gründen wurde ein Großteil der fachlichen Logik direkt im BI-Tool (OAS, damals OBIEE) entworfen – die Entwicklungszyklen boten keinen Platz für die vorherige Ausgestaltung von ETL-Prozessen.
Lange Wartezeiten
Aus diesen Gründen ist das Datenmodell des Data Mart, aus dem die Berichte versorgt werden, nah an der Datenquelle gestaltet. Die Fakten und Dimensionen sind nicht so gestaltet, dass die Berichte direkt versorgt werden können. Dazu kommt, dass es mehrere Zeitstrahlen gibt, an denen sich die Daten ausrichten (Bi-/Tritemporale Historisierung nach der Zeit des Auftauchens der Datensätze im DWH sowie mehrerer fachlicher Zeitlinien). Die daraus resultieren SQL-Abfragen des OAS sind dementsprechend aufwendig und müssen oft mehrere Fakten miteinander verbinden. Das führte zu langen Wartezeiten beim Erstellen der Berichte. Der Zugriff auf die Standardberichte ist schneller, wenn der OAS diese bereits einmal ausgeführt hat und im Cache hält. Daher werden diese jeden Morgen einmal mit Hilfe eines OAS-Agenten ausgeführt. Das kann aber nur mit einigen wenigen Standardwerten erfolgen. Soll ein individueller Bericht ausgegeben werden, ergeben sich nach wie vor noch längere Wartezeiten.
Ein Datamart in Kleidergrößen
Um die Datenmengen, die kombiniert werden müssen, zu reduzieren, wurden Tabellen mit dem Suffix „XS” eingeführt – angelehnt an die extra kleine Kleidergröße. In den XS-Tabellen werden nur die Fakten der gängigsten Anfrageintervalle aufgenommen. Dieser Prozess wurde in einer Zeit entwickelt, in der es nicht gelang, das OAS Repository so einzurichten, dass das Partitionierungskriterium zuverlässig aufgenommen wurde. Bei der Planung der In-Memory-Konfiguration erwies sich der XS-Datamart neben dem nur noch als Archiv genutzten vollständigen Datamart in Größe L als sehr hilfreich. Denn der gesamte Inhalt der XS-Größe passt in den 16GB-Storage, der für die nutzbaren Daten als maximale Größe (Base-Level-Lizenzvariante) durch Oracle vorgegeben ist.
Beauftragung und Einrichtung
Eine separate Beauftragung oder Installation der In-Memory-Option war nicht erforderlich. Lediglich die SGA (System Global Area – Speicherbereich der Oracle Datenbank) wurde vergrößert, um Platz für die In-Memory-Area zu schaffen. Die Konfiguration dafür bestand aus dem Setzen von drei Initialisierungs-Parametern:
alter system set inmemory_force=base_level scope=spfile;alter system set inmemory_size=16G scope=spfile;alter system set sga_target=42G scope=spfile; |
Die Datenbank verfügt über 90 GB RAM in der Produktionsinstanz.
Anschließend ist die angepasste Konfiguration zum Beispiel im AWR-Bericht wie folgt zu sehen:

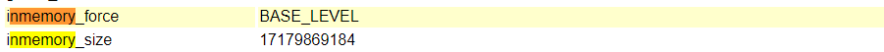
Der Parameter INMEMORY_SIZE wird in der CDB eingestellt.
Funktionsweise der In-Memory-Option
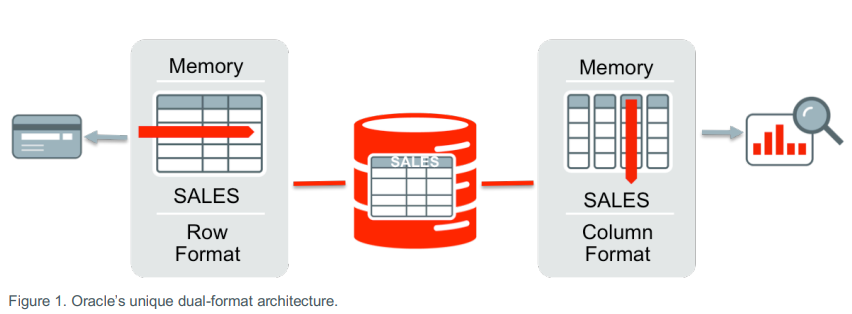
Bei der Oracle In-Memory-Option handelt es sich um eine Erweiterung der relationalen Datenbank von Oracle. Die Daten werden zusätzlich zur bisherigen Speicherung in der Datenbank auch im Arbeitsspeicher des Datenbankservers gehalten, und zwar im sogenannten „Column Store”. Dabei werden die Daten mittels einer speziellen Komprimierungstechnik (Columnar Compression) stark komprimiert. Je nach Konfiguration sind Kompressionsraten zwischen 2 und 20 möglich.
Der entscheidende Unterschied zwischen einem reinen Caching der Zugriffe, wie im Database Buffer Cache, und dem In-Memory-Column-Store liegt darin, dass für In-Memory die Daten nicht zeilenweise (bzw. als Tabellenblöcke) in den Arbeitsspeicher geladen werden, sondern spaltenweise komprimiert im RAM gehalten werden. Diese Speichermethode erlaubt sehr effiziente Abfragen auf einzelne oder wenige Spalten von großen Tabellen mit vielen Zeilen, die mittels Filtern eingeschränkt und aggregiert werden. Diese Art von Abfragen kommen typischerweise in Data Warehouses vor.
Ist die In-Memory-Option aktiviert, stehen die Daten sowohl zeilenweise als auch spaltenweise (im In-Memory-Column-Store) zur Verfügung. Je nach Art der Abfrage wird auf die einzelnen Tabellenblöcke (auf Disk oder via Buffer Cache) oder auf den Column Store zugegriffen. Änderungen werden im Column Store nachgeführt, sodass die In-Memory-Option ohne applikatorische Anpassungen verwendet werden kann.
Das Base Level Feature unterstützt alle In Memory Funktionen außer:
- Automatic In-Memory (AIM)
- Compression levels außer MEMCOMPRESS FOR QUERY LOW
- Excluded columns (Es werden immer alle Spalten einer Tabelle geladen)
- CELLMEMORY Feature in Exadata
Alle anderen Database In-Memory Features wie In-Memory Expressions, Join Groups, Automatic Data Optimization (ADO) und FastStart stehen zur Verfügung.
Auslagern der XS-Tabellen in die In-Memory-Area
Die Faktendaten in unserem Projekt haben einen Umfang von ca. 45 GB (420 Millionen Zeilen), dazu kommen 116 MB Dimensionen (2 Millionen Zeilen).
Der XS-Datamart hat aktuell einen Umfang von 11 GB (150 Millionen Zeilen). Es sind ein Jahr Abrechnungsdaten enthalten, allerdings inklusive der aktuell bestehenden Referenzen zwischen XS- und XL-Daten.
Die XS-Tabellen entstehen, indem zuerst die Daten für die kompletten Tabellen zusammengerechnet und dann die überflüssigen Daten wieder entfernt werden. All dies erfolgt im Rahmen der nächtlichen Beladung mit dem Oracle Data Integrator (ODI).
Die relevanten Tabellen des XS-Datamarts werden anschließend mittels „ALTER TABLE INMEMORY” in den In-Memory-Bereich geladen. Hierfür wurden PL/SQL-Prozeduren in einem bestehenden PL/SQL-Package angelegt, die den XS-Datamart be- und entladen.
Leistungssteigerung in den Abfragen
Nach dem erstmaligen Einrichten der In-Memory-Area wurden zunächst einige bekannte Abfragen in der Entwicklungstestumgebung ausgeführt, die für ihre langen Antwortzeiten bekannt waren:
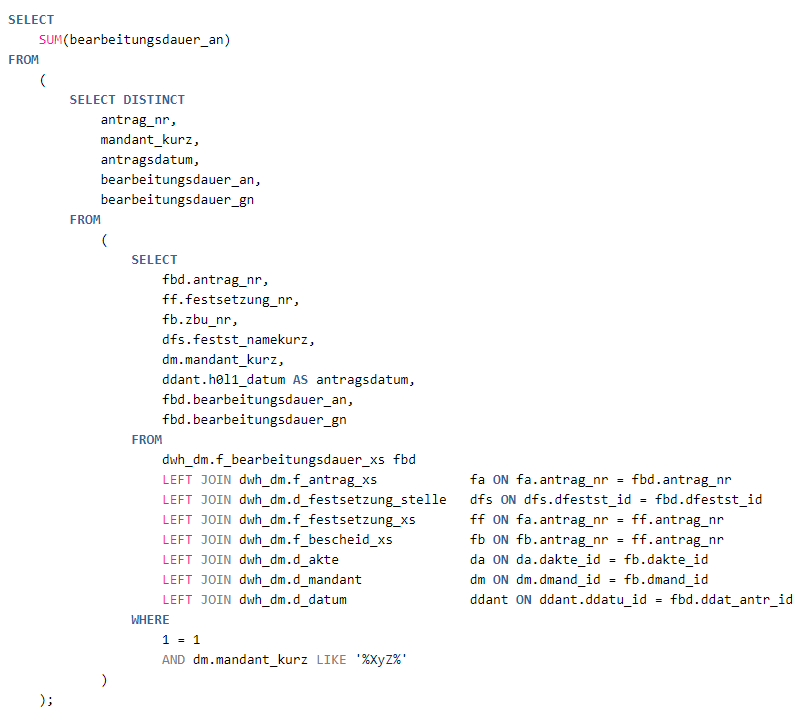
Die Laufzeit des obigen Statements war:
| Test | Laufzeit s | Plan |
| Archiv-Tabellen | 7,8 | |
| XS-Tabellen ohne IM | 4 | Hash Join. Nested Loops, Full Scan, Fast Full Scan, Range Scan |
| XS mit IM | 0,233 | Hash join, inmemory full |
Ergebnisse für die Anwender
In den Ausführungsplänen des oben genannten Statements in der Produktion lassen sich die In-Memory-Zugriffe gut erkennen.
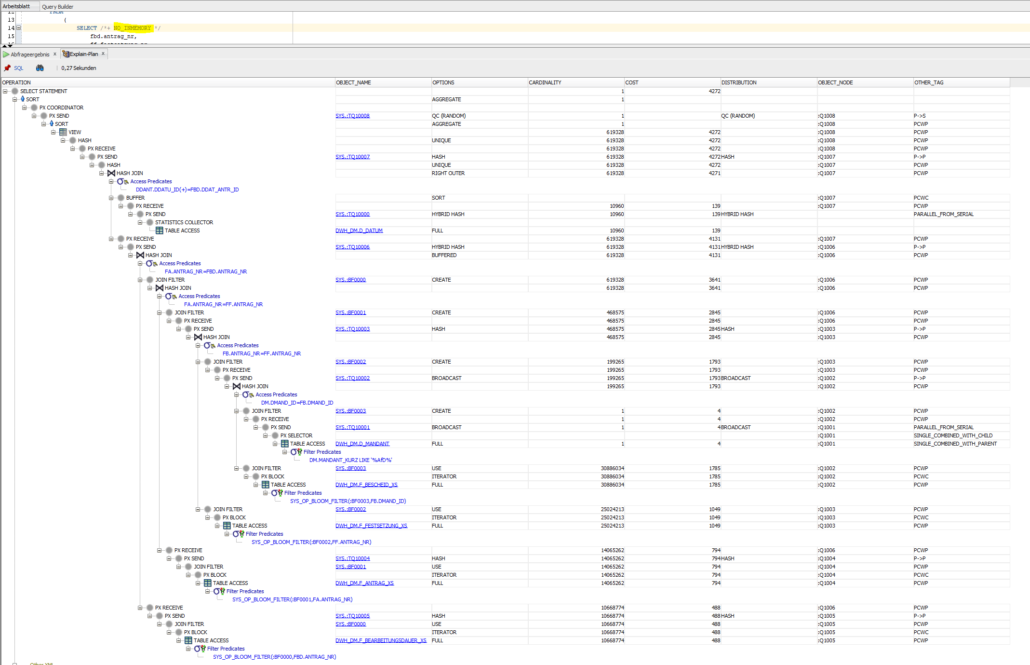

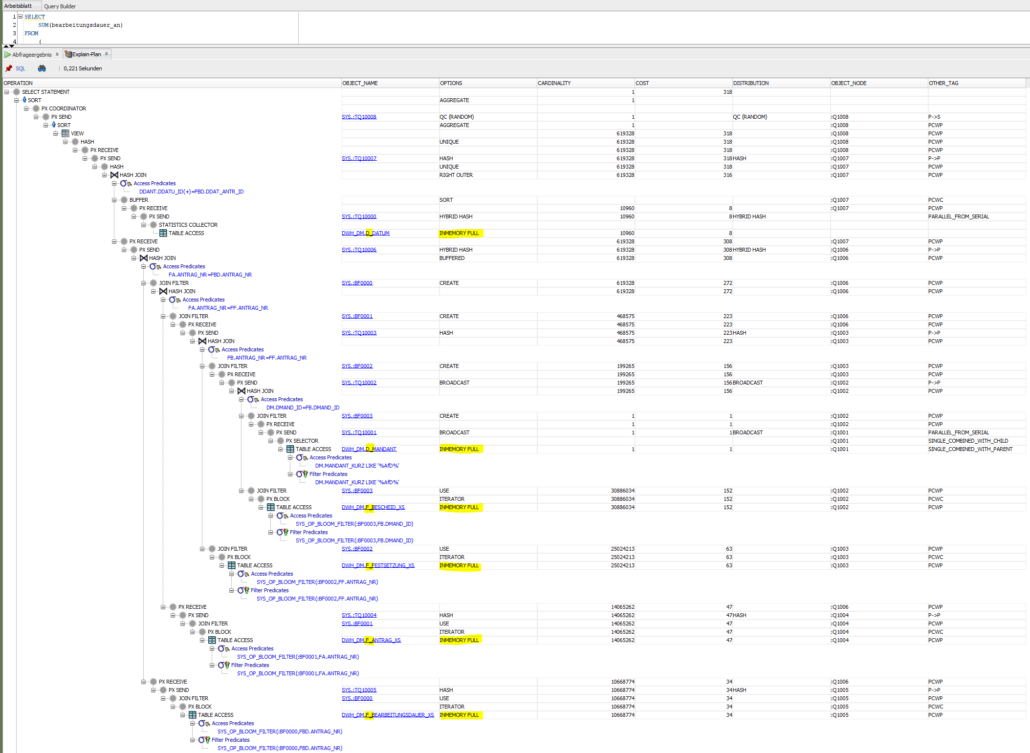
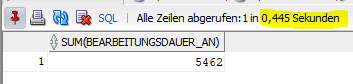
Die Performance-Steigerung nur in diesem Fall beträgt bei einer Antwortzeit von 0,445 statt 3,359 Sekunden fast Faktor 8.
Beobachtung des In-Memory-Bereiches
Der Füllstand der In-Memory-Area lässt sich mit einer einfachen View beobachten:
SELECT
sum (trunc(
used_bytes /(1024 * 1024 * 1024), 2
)) "USED_GB"
FROM
v$inmemory_area;
1MB POOL 11934892032 6936330240 DONE 3
64KB POOL 5212274688 81920000 DONE 3Während des Betriebes kann man die Arbeit der In-Memory-Option beim Befüllen des Speicherbereiches auch im AWR-Report beobachten:
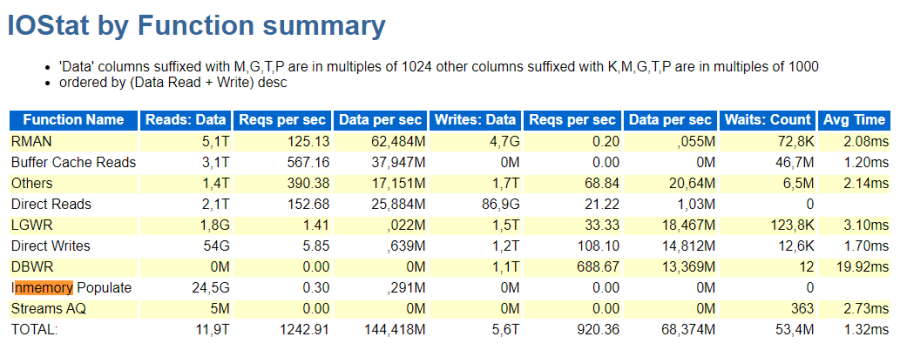
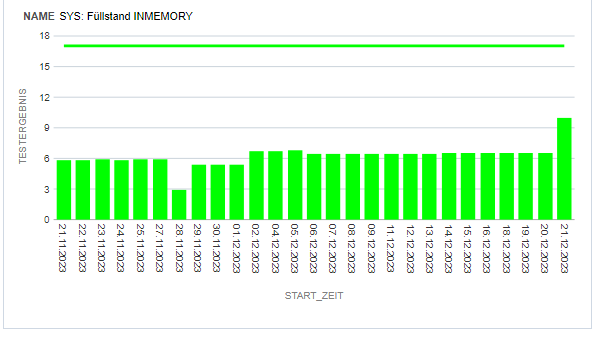
Den Füllstand des In-Memory-Speicherbereiches beobachten wir in einem einfachen OAS-Bericht.
Fazit
Ist es möglich, einen Datamart zu erzeugen, der nicht größer als 16GB ist, kann man die kostenfreie BASE LEVEL Variante der Oracle-In-Memory Option durchaus mit messbarem Erfolg einsetzen. Dies erfordert allerdings bei nichttrivialen DWH-Größen die Entwicklung eines Frameworks, das diesen reduzierten Datamart auch pflegt. Wir erledigen das im ODI und mit PL/SQL. Es muss allerdings auch im OAS eine Subject-Area für den reduzierten Bereich erstellt werden. Das ist ein Mehraufwand, den das Projekt für eine in entscheidenden Teilen achtfache Beschleunigung zu tragen gewillt ist.